

Machine Learning with XGBoost and Scikit-learn

XGBoost is an open-source Python library that provides a gradient boosting framework. It helps in producing a highly efficient, flexible, and portable model.
When it comes to predictions, XGBoost outperforms the other algorithms or machine learning frameworks.
This is due to its accuracy and enhanced performance. It combines several models into a single model to correct the errors made by existing models.
In this tutorial, we will use Scikit-learn to build our model. We will then improve the model's accuracy and performance using XGBoost.
Table of contents
- Prerequisites
- Introduction
- Dataset
- Loading the dataset
- Checking missing values
- getting started with categorical encoding
- Installing XGBoost
- Dataset splitting
- Decision tree classifier
- Building a model using decision tree classifier
- Testing model
- XGBoost
- Making predictions using XGBoost
- Conclusion
- References
Prerequisites
To follow along, you should:
- Install Python.
- Have good knowledge of Python.
- Be familiar with machine learning modeling and supervised learning algorithms
- Know how to use Pandas, Numpy and Google Colab to build a model.
You can read more about Boost algorithms from here.
Introduction
XGBoost is built on top of a gradient boosting framework.
Gradient boosting is a machine learning technique used for classification, regression, and clustering problems. It optimizes the model when making predictions.
In this technique, different models are grouped to perform the same task.
The base models are known as weak learners. They work on the principle that a weak learner makes poor predictions when alone, but produces the best prediction when in a team.
XGBoost creates a strong learner based on weak learners. It adds models sequentially. Therefore, the weak models' errors are corrected by the next models in the chain to achieve an optimized solution. This is known as ensembling.
You can read more about ensemble methods here
Reasons for using XGBoost
- High execution speed.
- Improved model performance.
- Reduced model errors.
In this tutorial, we will build a classification model that predicts if customers will subscribe to a bank's term deposit.
A term deposit is a fixed investment plan. Term deposits may have a short-term or long-term maturity.
We will train and build our model using a dataset that contains customers' information.
Dataset
The dataset contains important attributes that the model will use during training.
It uses this information to determine if a person will subscribe to a term deposit or not. The dataset also contains the following additional information:

We need to clean this dataset before using it for training and predictive analysis.
To download the dataset, click here.
Data analysis (EDA) packages
Let's load all the packages that we will use for data analysis and manipulation.
We will use Pandas to load and clean our dataset. Numpy will be used for mathematical and scientific computations.
import pandas as pd
import numpy as np
Loading the dataset
Let's load the dataset using Pandas:
df = pd.read_csv("bank-additional-full.csv", sep=";")
We specify the fields separator in the dataset as sep=";".
This is because, the fields in our dataset are separated by ; and not the default , separator.
To see the structure of our dataset, run this code:
df.head()
The output is shown below:

Let's see the available data points in our dataset.
df.shape
The output is as shown:
(41188, 21)
The output shows that our dataset has a total of 41188 data points and 21 columns.
Let's see what these columns are:
df.columns
The output is shown in the image below:

We will train our model using columns such as age, job, marital, education, and housing.
In the above output, the y column is used as the target variable. This is what we are trying to predict.
The y column is labeled either yes or no.
yes shows that a customer will subscribe to the term deposit, and no means that the person will not subscribe.
Let's start cleaning our dataset, we start by checking for missing values.
Check missing values
We use the following command to check for missing values:
df.isnull().sum()
The output is shown in the image below:

The results show that our dataset has no missing values.
Dataset cleaning also involves checking for data types in columns, as shown below:

In the above image, we have different data types such as int64, object, and float64. Note that the values in the object data types are in form of categories.
For example, the job column contains an object data type. It has job categories such as housemaid, services, blue-collar, and technician.
The marital column has categories such as single, married, and divorced.
Machine learning doe not work with these categorical data. We, therefore, need to convert these categorical values into numeric values.
We will convert all the data types into int64. We do not need to convert the float64 datatype because it's already in numeric value.
The process of converting categorical values into a numeric value is called categorical encoding.
Getting started with categorical encoding
Before we start, let's retrieve all columns with the object datatype.
df.columns[df.dtypes == 'object']
The output is shown:

To convert all columns into numeric values, we use the get_dummies() method.
get_dummies() is a Pandas method for converting categorical data into encoded numerical values, which are in a machine-readable format.
pd.get_dummies(df,df.columns[df.dtypes == 'object'])
This will output a new dataset with encoded numeric values, as shown below:

The above output shows the first 17 columns with encoded numeric values.
For a detailed understanding and practical guide on how the get_dummies() method works, read this guide
Let's check if the column's data types have changed.
df.dtypes
The output is as shown in the image below:

This shows that all objects in the columns were converted into int. We can now start building our model.
In this section, we will build our model using a basic Scikit-learn algorithm. We will then improve the model performance using XGBoost.
Installing XGBoost
Let's install XGBoost using the following command:
!pip install xgboost
Let's import this package.
import xgboost as xgb
Now that we have imported XGBoost, let's split our dataset into testing and training sets.
Dataset splitting
We need to import train_test_split for dataset splitting.
import train_test_split from sklearn.model_selection
The dataset is split into two sets: a training set and a testing set. 80% of the dataset will be used as a training set and 20% will be used for testing.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
To understand the power of XGBoost, we need to compare it with another algorithm.
We first use the decision tree classifier algorithm to build the model.
After that, we build the same model using XGBoost and compare the results to see if XGBoost has improved the model performance.
Let's start with a decision tree classifier.
Decision tree classifier
A decision tree classifier is a machine learning algorithm for solving classification problems. It's imported from the Scikit-learn library.
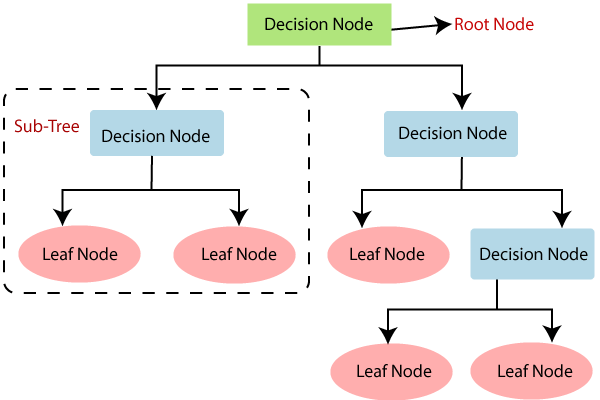
The decision tree is made up of branches that are used for strategic analysis when formulating a decision rule.
Decision trees create a model that will predict the labeled variable based on the input data.
When building a model, the internal nodes of the tree are used to represent the unique features of a given dataset.
The tree branches represent the decision rules and each leaf node represents the prediction outcome.
This is shown in the image below:

from sklearn.tree import DecisionTreeClassifier
Let's initialize the DecisionTreeClassifier.
dTree_clf = DecisionTreeClassifier()
After initializing the DecisionTreeClassifier, we can now use it to build our model.
Building the model using decision tree classifier
We fit our model into the training set. This enables the model to understand and learn patterns. This is important for predictive analysis.
dTree_clf.fit(X_train,y_train)
After training, this is the output:
The output highlights the parameters used by the model to achieve the best solution when making a prediction.
These parameters are as follows:
class_weight- This assigns weights to the algorithm's classes.criterion- It's used to measure how the nodes are split.max_depth- The maximum depth of the decision tree classifier.max_features- The total number of unique characteristics in the dataset.max_leaf_nodes- The total number of leaf nodes in the decision tree.min_impurity_decrease- This reduces the impurities when splitting the nodes.min_impurity_split- This ensures that the best criteria are met when splitting the nodes.min_samples_leaf- The minimum samples when creating a leaf node.min_samples_split- The minimum samples when splitting a node.min_weight_fraction_leaf- The minimum weight of a leaf.random_state- These numbers are used when performing each split.splitter- This is the best strategy used to split each node.
Let's test this model.
Testing model
We test the model using the test dataset. It allows us to check the performance of the model after the training phase.
y_pred2 = dTree_clf.predict(X_test)
To view the predictions, use this command:
y_pred2
The output is, as shown below:
array([1, 0, 0, ..., 1, 0, 0], dtype=int8)
For the first value in the array, the model has made a positive prediction (1). This shows that a person will subscribe to a term deposit in the bank.
This output only shows the prediction of a few data points.
Let's calculate the accuracy score of these predictions:
print("Accuracy of Model::",accuracy_score(y_test,y_pred2))
The output is as shown:
Accuracy of Model:: 0.8929351784413693
This shows that the model has an accuracy score of 89.29% when making predictions.
Let's see if XGBoost can improve the performance of this model and increase the accuracy score.
XGBoost
We first need to initialize XGBoost. As discussed, XGBoost creates the best model based on other weak models.
When different models are combined, they boost the process of correcting errors when making a prediction.
XGBoost can increase the model's accuracy score by using the best parameters during prediction.
xgb_classifier = xgb.XGBClassifier()
After initializing XGBoost, we can use it to train our model.
xgb_classifier.fit(X_train,y_train)
Once again, we use the training set. The model learns from this dataset, stores the knowledge gained in memory, and uses this knowledge when making predictions.
xgb_classifier.fit(X_train,y_train)
The output is as shown:

XGBoost adds more parameters to the model. The added parameters are used to remove errors during training, as well as increase the model performance.
The model parameters are as follows:
base_score- This is the prediction for initial models. It has a default score of0.5.booster- This is the type of algorithm that is used to improve the model performance.colsample_bylevel- This shows how different branches levels are separated in the tree.colsample_bynode- It shows how different nodes are split.colsample_bytree- It shows how different trees in XGBoost are separated.gamma- This is used to reduce the loss when correcting model errors.learning_rate- The rate at which the XGBoost model learns during the training phasemax_delta_step- This is used to update the model class during training.max_depth- This is the maximum depth of the XGBoost classifier.min_child_weight- This is the minimum size we are allowed to partition the tree's leaf node.n_estimators- This is the total number of estimators added during model training.n_jobs- This is the total number of jobs handled by the model.objective- It specifies the type of algorithm used to build the model, in this case, it uses logistic regression.random_state- This seeding number is used by the model.reg_alpha- This is the parameter used to reduce the weights of the model.reg_lambda- This is the parameter used to increase the weights of the model.seed- The seed used by the model.subsample- The ratios we use to sample the training phases of a model.verbosity- It measures the verbosity of words in the dataset.
Let's test this model and make a prediction.
This will test our model so that we can know how well it learned during the training phase.
Making predictions using XGBoost
predictions = xgb_classifier.predict(X_test)
To view the prediction results use this command:
predictions
The output is as shown:
array([0, 0, 0, ..., 1, 0, 0], dtype=int8)
In this prediction, the first value in the array has been predicted as 0. This is different from the prediction made by the decision tree classifier.
This shows that XGBoost has corrected the prediction error and thus, made accurate predictions.
Let's see if it has increased the accuracy score.
print("Accuracy of Model::",accuracy_score(y_test,predictions))
The accuracy score is as shown:
Accuracy of Model:: 0.9225540179655256
This shows that the model has an accuracy score of 92.255%. This is an increased accuracy score compared to 89.29% that was made by the decision tree classier.
This concludes that XGBoost reduces model errors during predictions and improves the model performance.
Conclusion
In this tutorial, we have learned how to make a machine learning model with XGBoost and Scikit-learn. We started by stating the benefits of XGBoost.
To understand how XGBoost is a great machine learning library, we compared it to the decision tree classifier algorithm to build the model. After that, we built the same model using XGBoost.
From the results, XGBoost was better than the decision tree classifier. It had increased the accuracy score from 89.29% to 92.255%.
You can, therefore, use the knowledge gained from this tutorial to build better machine learning models with XGBoost and Scikit-learn.
To get the Google Colab code for this tutorial, click here
Further learning
- Code for this tutorial
- Scikit-learn documentation
- XGBoost documentation
- Basics of ensemble learning
- Boosting algorithms in Python
Peer Review Contributions by: Srishilesh P S












Cloudzilla is FREE for React and Node.js projects









{kind=link}