Supervised Learning Algorithms

Artificial intelligence is the art of embedding intelligence into machines. The current era is an exciting one to live in, due to the advances in technology being guided by huge amounts of data and intelligence. The translation services that we use, voice assistants that simplify our tasks, ride-hailing services such as Uber, and map services used for navigation are all examples of how AI is being leveraged and is creating a massive impact. <!--more-->
Introduction to Machine Learning
Machine learning is a subset of artificial intelligence. Artificial intelligence deals with automating knowledge or judgment tasks on an application level. Considering the overall vision, artificial intelligence aims to attain artificial general intelligence (AGI). Human intelligence is an example of AGI. The entire field of AI is working towards one goal: AGI. Machine learning, on the other hand, focuses on the statistical approach of attaining human-level intelligence.
Tom Mitchell defines machine learning as follows: 'Machine learning is the study of computer algorithms that allow computer programs to automatically improve through experience'. One of the main objectives of machine learning is to extract patterns from data.
The method of feeding experience to the algorithm is the basis for the primary categorization of algorithms. Under machine learning, we mainly study three types of algorithms:
-
Supervised Learning: Supervised learning algorithms receive a pair of input and output values as part of their dataset. The pair of values help the algorithm model the function that generates such outputs for any given inputs. We will be covering the entire topic of supervised learning in this article.
-
Unsupervised Learning: In this type of learning, algorithms are only fed in as input data variables. The algorithms make sense of the data based on patterns that the algorithm detects. For example, given a dataset of black and red cards, clustering algorithms will find all cards similar to black and place them in one set. In the other set, the red cards are placed. Thereby, a decision boundary is formed. Clustering is one such example of unsupervised learning.
-
Reinforcement Learning: Reinforcement learning is a subset of machine learning that deals with agents performing actions in a simulated environment. The outcome of the actions carries a reward. The objective is to optimize the reward obtained through actions in the environment. Most of the living ecosystem is best modeled by a reward-based mechanism. For example, a child likes to eat candy again and again, because it provides a dopamine rush (every time) that is the reward.
Supervised Learning
Let us look at a few of the applications of supervised learning before we dive into the algorithms. Supervised learning tasks require datasets with input-output pairs. Consider the example of trying to classify the digits. Given an image of a digit, what is the number? MNIST digits dataset is one of the earliest datasets that helped automate the processes of postal services.
Another use case example of supervised learning is predicting the price of houses given a few features. The features can include size, location, facilities, etc. The input consists of the features and the output consists of the price. Algorithms that predict continuous values of data are called regression-based algorithms.
Supervised learning is mainly classified into two types: Classification and Regression. Let us take a closer look at both these algorithm categories.
Classification
Classification algorithms are a type of supervised learning algorithms that predict outputs from a discrete sample space. For example, predicting a disease, predicting digit output labels such as Yes or No, or 'A','B','C', respectively. We can also have scenarios where multiple outputs are required. For this use case, we can consider the example of self-driving cars.
The various objects found on the road need to be classified according to their categories and also need to be classified as safe or unsafe. This scenario is an example of multi-class classification. We will now look at some of the key algorithms underneath the classification algorithms.
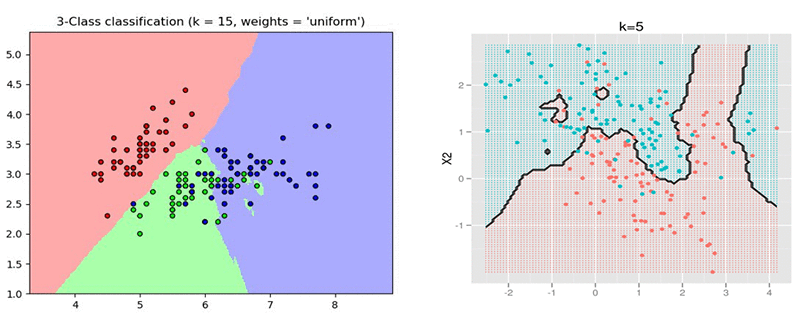
- K-Nearest Neighbors(KNN): KNN is an algorithm that works on creating a decision boundary based on distance metrics. Distance metrics define and parameterize distance. There are various distance metrics such as Euclidean distance, Manhattan distance, etc.

All machine learning algorithms have hyperparameters to deal with. In K-NN, the parameter is k. It is initialized to an integer depending on the number of classes in the dataset known before fitting. k signifies the number of nearest points the algorithm considers while creating decision boundaries.

# Import necessary modules
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits
# Create feature and target arrays
digits = load_digits()
X = digits.data
y = digits.target
# Split into training and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=42, stratify=y)
# Create a k-NN classifier with 7 neighbors: knn
knn = KNeighborsClassifier(n_neighbors=7)
# Fit the classifier to the training data
knn.fit(X_train, y_train)
# Print the accuracy
print(knn.score(X_test,y_test))
The output is shown below:
0.9833333333333333
The accuracy of the classifier is 98.33%. This is tested on the test dataset. 98.33% is a good accuracy percentage, but the dataset is a simple one. 10 years ago, this number would have been a considered good one.
- Support Vector Machines(SVM): SVMs are maximum margin classifiers that are optimized to find an N-dimensional hyperplane in an N-dimensional space. The objective is to find the hyperplane that has the maximum margin from all the classes. Let's understand a few of the concepts and terminologies used in SVM.
- Support Vector: Vectors that are closest to the hyperplane are called support vectors.
- Margin: Margin is defined as the distance between data points and the hyperplane.
- Hyperplane: The decision boundary which satisfies the maximum margin condition is called the hyperplane.
The reasoning behind SVM is to find the hyperplane with the maximum distance from the support vectors. The hyperplane may be a linear decision boundary or a non-linear decision boundary. When dealing with non-linear planes, the dataset is projected into higher dimensions to create linear boundaries. For example, consider the following image.

The input space is transformed using kernels. SVM kernels are functions that take low-dimensional input space and transform them into higher dimensional space where the data is linearly separable. Some of the kernels commonly used are:
- Linear Kernel
- Polynomial Kernel
- Radial Basis Function Kernel
Let us look at implementing SVM using sklearn.
# Import necessary modules
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits
# Create feature and target arrays
digits = load_digits()
X = digits.data
y = digits.target
# Split into training and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=42, stratify=y)
# Create a SVM classifier
classifier = svm.SVC(kernel='poly')
classifier.fit(X_train, y_train)
print(classifier.score(X_test,y_test))
Regression
Regression algorithms are another subset of machine learning algorithms used to predict continuous numeric responses. As seen in an earlier example, predicting house rent given different factors is an example of regression. Let's look at the regression algorithm and use linear regression as an example.
-
Linear Regression: Linear regression is a simple yet effective method used in a large number of applications. Let's say we have an input feature vector
x. The output feature vectoryis the predicted entity. We use the sum of least squares to compute the relation between the target and input variables. Linear regression can be implemented using sklearn. Let us look at the implementation below:# Import necessary modules from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.datasets import load_digits import numpy as np import matplotlib.pyplot as plt # Create feature and target arrays digits = load_digits() X = digits.data y = digits.target # Split into training and test set X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=42, stratify=y) linear_regression = LinearRegression() linear_regression.fit(X_train,y_train) print(linear_regression.score(X_test,y_test))
The output of the print statement will be 0.55. The scoring metric used for linear regression is the R^2 metric. Pronounced as R-squared, it tells us about the effectiveness of the curve-fitting on the graph. The curve is a synonym for the equation that models the actual data. Since we are trying to model the actual data with an equation, we name the process curve fitting.
The curve needs to not have any bends as well, that is, it can be linear or non-linear. The complexity of the data is a parameter that decides the degree of the equation. The scoring metric helps us decide a suitable complexity(degree of the equation) used to model the data. The closer the value of the scoring metric, R-squared, is to 1, the higher chances of good curve fitting.
Curve fitting may lead to overfitting when the number of features considered is less. Overfitting refers to a scenario where the model performs very well on the data it has seen. But its performance drops when it works on unseen data. Underfitting is also a possibility when we don't have sufficient data to train the model(s) with.
Conclusion
We have looked at supervised learning and went over a few code snippets to implement these algorithms using scikit-learn. Scikit-learn is a very powerful and elegantly written library. I hope this serves as an introduction to your machine learning journey.


{kind=link}