Multi-Label Classification with Scikit-MultiLearn

Multi-label classification allows us to classify data sets with more than one target variable. In multi-label classification, we have several labels that are the outputs for a given prediction. When making predictions, a given input may belong to more than one label. <!--more--> For example, when predicting a given movie category, it may belong to horror, romance, adventure, action, or all simultaneously. In this example, we have multi-labels that can be assigned to a given movie.
In multi-class classification, an input belongs to only a single label. For example, when predicting if a given image belongs to a cat or a dog, the output can be either a cat or dog but not both at the same time.
In this tutorial, we will be dealing with multi-label text classification, and we will build a model that classifies a given text input into different categories. Our text input can belong to multiple categories or labels at the same time.
We will use scikit-multilearn in building our model. Scikit-multilearn is a python library built on top of scikit-learn and is best suited for multi-label classification.
Table of contents
- Problem transformation
- Adapted algorithm
- Ensemble methods
- Dataset
- Loading exploratory data analysis packages
- Checking data structure
- Datatype of our labels
- Loading machine learning packages
- Installing Scikit-Multilearn
- Importing problem transformation packages
- Text preprocessing
- Exploring the dataset for noise
- Extracting stop words
- Removing stop words
- Feature engineering
- Dataset split
- Building the model
- Making a single prediction
- Conclusion
- References
Prerequisites
A reader must have:
- A good understanding of Python.
- A good understanding of machine learning modeling.
- Download the dataset here.
- Have some knowledge of Pandas and Numpy.
NOTE: To follow along easily, use Google Colab to build your model.
Multi-label classification originated from investigating text categorization problems, where each document may belong to several predefined topics simultaneously.
Multi-label classification of textual data is a significant problem requiring advanced methods and specialized machine learning algorithms to predict multiple-labeled classes.
There is no constraint on how many labels a text can be assigned to in the multi-label problem; the more the labels, the more complex the problem. To solve these problems, we have different methods and techniques specific to multi-label classification.
These methods and techniques are as follows:
- Problem transformation.
- Adapted algorithm.
- Ensemble methods.
Problem transformation
It refers to converting the multi-label dataset into a single-label dataset.
Single-label datasets and problems are machine-readable and make it easy with model building. Problem transformation is done using the following techniques:
- Binary relevance
- Classifier chains
- Label powerset
Binary relevance
This technique treats each label independently, and the multi-labels are then separated as single-class classification.
Let's take this example as shown below.
We have independent features X1, X2 and X3, and the target variables or labels are Class1, Class2, and Class3.
In binary relevance, the multi-label problem is split into three unique single-class classification problems, as shown in the figure below.

When using this technique, label correlation may be lost hence we introduce a second technique.
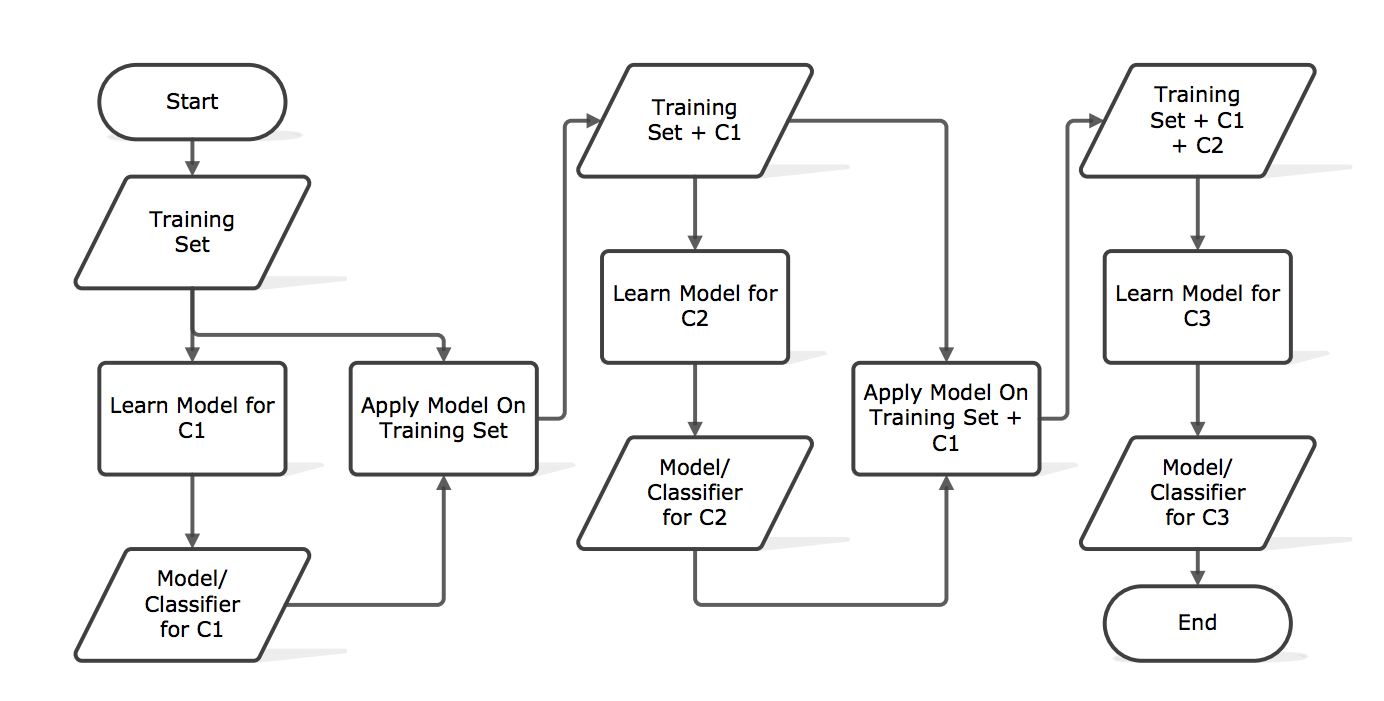
Classifier chains
In this technique, we have multiple classifiers connected in a chain. The first classifier is built using the input data. The following classifiers are trained using the combined inputs and the previous classifiers in a given chain.
This is a sequential process where an output of one classifier is used as the input of the next classifier in the chain.
This process is shown in the image below:

To give a more detailed understanding, let's use this example as shown in this image.

In the image above, the green-colored boxes are the combined inputs, and the remaining part represents the target variable or label. As seen, it forms a chain where the output of one classifier is used as the input of the next classifier. All of this is done in sequential order.
This technique preserves label correlation, thus solve the problem encountered by the binary relevance technique. However, it gives a lower accuracy, therefore, we introduce a third technique.
Label powerset
It transforms the problem into a multi-class problem. Each multi-class classifier is then trained with unique label combinations found in the data.
The goal of the label powerset is to find a combination of unique labels and assign them different values. Let's see an example.

In this example we have three unique label combination, it is then assigned values 1, 2 and 3. The multi-class classifier is then trained on all three unique label combinations.
This technique tends to give higher accuracy.
Adapted algorithm
This technique uses adaptive algorithms, which are used to perform multi-label classification rather than conducting problem transformation directly. In Scikit-multilearn, we have multi-label-k-nearest-neighbor (MLkNN), which is used to handle multi-label classification.
Ensemble methods
This is a hybrid technique that combines the functionalities of the two mentioned techniques to produce better results. Ensemble methods tend to give a model with a higher accuracy score.
For a detailed understanding about ensemble methods, read this article.
NOTE: In this tutorial, we will focus on the first technique, problem transformation, in building our model.
Before we start building our model, let's see the dataset that we will be using.
Dataset
As mentioned earlier, we will build a multi-label text classification, and the model will be able to classify given text into different categories.
The categories in our dataset are mysql, python, and php. A text can belong to one or more of the given categories. If a text belongs to a certain category, it is assigned 1; if it does not, it is assigned 0 as shown in the image below.

To download the CSV file for this dataset, click here. After downloading the dataset, name it as dataset-tags.csv.
Loading exploratory data analysis packages
Exploratory data analysis(EDA) packages are used for data analysis and data manipulation. We shall use pandas to read our dataset and numpy to perform mathematical computations.
import pandas as pd
import numpy as np
We use pandas to load our dataset.
df = pd.read_csv("dataset-tags.csv")
Checking data structure
We check the structure to be able to see the available columns in our dataset.
df.head()
The output is as shown:

The image above shows the columns in our dataset. These columns are as follows:
- The
titlecolumn contains the texts used as input for our model during training. - The
tagscolumn contains the various labels that are assigned to our input text. These tags arephp,mysqlandpython. - The
mysqlcolumn is used to classify a text that belongs to themysqlclass. If it ismysqlit's assigned1and0if not related. - The
phpcolumn used to classify a text that belongs to thephpclass. If it isphpit's assigned1.0and0.0if not related. - The
phpcolumn is used to classify a text that belongs to thepythonclass. If it ispython, it's assigned1.0and0.0if not related.
From the image above, we can see that some texts belong to the different classes simultaneously. The text in the first row belongs to both mysql and python.
Datatype of our labels
We check the data type of our labels as they need to have a uniform data type.
df.dtypes
The output is as shown:
title object
tags object
mysql int64
python float64
php float64
dtype: object
As seen, the mysql label is an integer. We need to convert the datatype from integer to float so that all the labels can have a uniform data type.
We convert integer to float using the astype(float) method.
df['mysql'] = df['mysql'].astype(float)
Now that our dataset is clean, let's import the machine learning packages.
Loading machine learning packages
from sklearn.naive_bayes import GaussianNB,MultinomialNB
from sklearn.metrics import accuracy_score,hamming_loss
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
In the above code snippet, we have imported the following.
MultinomialNBis a method found in the Naive Bayes algorithm used in building our model, and it is best suited for classification that contains discrete features such a text. For a detailed understanding aboutMultinomialNB, click hereaccuracy_scoreis used to calculate the accuracy of our model when making predictions. The accuracy score is usually expressed in percentages.hamming_lossis used to determine the fraction of incorrect predictions of a given model.train_test_splitis a method used to split our dataset into two sets; train set and test set.TfidfVectorizeris a statistical measure that evaluates how relevant a word is to a document in a collection of documents. It does this by checking the frequency in which words appear in a certain document. If a word commonly occurs in a document, it is less relevant than a word that is rare in a document. For detailed understanding aboutTfidfVectorizerclick here
Installing Scikit-Multilearn
Since we are using Google Colab, we install this library using the following command:
!pip install scikit-multilearn
This is the library that we will use to perform multi-label text classification. As mention earlier, this tutorial will focus on problem transformation in building our model.
We need to import the required packages to handle the three problem transformation techniques. As explained earlier, the three techniques for problem transformation are binary relevance, classifier chains, and label powerset.
Importing problem transformation packages
We will use the problem transformation packages to handle the three techniques.
from skmultilearn.problem_transform import BinaryRelevance
from skmultilearn.problem_transform import ClassifierChain
from skmultilearn.problem_transform import LabelPowerset
Text preprocessing
Text preprocessing involves removing stop words and removal of noisy data. Stop words are a list of all words that are common in a given language.
Stop words are removed since they do not have a high classification power during predictive analysis. They tend to bring bias when building the classifier.
We remove noisy data that affect our model during training and bring errors in our model.
To perform text preprocessing, we need to install the neattext package. Neattext is a Python package used for textual data cleaning and text preprocessing.
Let's install it using the following command:
!pip install neattext
Let's load this package.
import neattext as nt
import neattext.functions as nfx
Exploring the dataset for noise
Noise is the unwanted character in our dataset that may affect our model during training.
df['title'].apply(lambda x:nt.TextFrame(x).noise_scan())
The output is as shown.
df['title'].apply(lambda x:nt.TextFrame(x).noise_scan())
0 {'text_noise': 11.267605633802818, 'text_lengt...
1 {'text_noise': 4.651162790697675, 'text_length...
2 {'text_noise': 9.90990990990991, 'text_length'...
3 {'text_noise': 8.47457627118644, 'text_length'...
4 {'text_noise': 2.631578947368421, 'text_length...
...
139 {'text_noise': 26.41509433962264, 'text_length...
140 {'text_noise': 3.8461538461538463, 'text_lengt...
141 {'text_noise': 6.666666666666667, 'text_length...
142 {'text_noise': 13.636363636363635, 'text_lengt...
143 {'text_noise': 7.142857142857142, 'text_length...
Name: title, Length: 144, dtype: object
We explore the noise data from the title column. It shows all the rows containing noise words from the first row 0 to 143 and the noise data in these rows. The first value is 11, and the last is 7. We can now extract the stop words from these noisy data.
Extracting stop words
We use the TextExtractor() and extract_stopwords() methods to extract all the stop words available in our title column.
df['title'].apply(lambda x:nt.TextExtractor(x).extract_stopwords())
The output of the stop words is shown:
0 [when, are, the, and]
1 [two, for]
2 [the, of, that, a, and, the, and]
3 [in, a, and, and]
4 [using]
...
139 [where, in, using]
140 [to]
141 [and, get, using]
142 [how, to, the, of, a, with, a, back, into, the]
143 [in, if]
Name: title, Length: 144, dtype: object
We can now remove the stop words.
Removing stop words
We remove stop words using the nfx.remove_stopwords function as shown:
df['title'].apply(nfx.remove_stopwords)
The output is as shown:
df['title'].apply(nfx.remove_stopwords)
0 Flask-SQLAlchemy - tables/databases created de...
1 Combining PHP variables MySQL query
2 'Counting' number records match certain criteria...
3 Insert new row table auto-id number. Php MySQL
4 Create Multiple MySQL tables PHP
...
139 Executing "SELECT ... ... ..." MySQLdb
140 SQLAlchemy reconnect DB
141 MySQL Count Distinct result PHP
142 store result radio button database value, data...
143 Use SQL count result statement - PHP
Name: title, Length: 144, dtype: object
The output gives a new dataset with all the stop words removed.
We can now save our clean dataset in a variable.
corpus = df['title'].apply(nfx.remove_stopwords)
Feature engineering
Feature engineering involves extracting features and properties from our data. Features are the independent units that are used for predictive analysis to influence the output.
We shall use the TfidfVectorizer() package to conduct feature extraction, which we imported earlier.
Let's initialize TfidfVectorizer(). We will use it to extract words from the texts in the dataset. It transforms the words into numeric values based on the frequency of each word that occurs in the entire text.
The numeric values will be the features for our model and are used as inputs for the model. Numeric values are more machine-readable than texts; that is why we convert the texts into numeric values.
For a detailed practical guide on how TfidfVectorizer works, click here.
tfidf = TfidfVectorizer()
After initialization, we can now start extracting the features.
Extracting features
The features will be numeric values as stated above. The features will be used as input for the model during training and predictive analysis.
Xfeatures = tfidf.fit_transform(corpus).toarray()
We extract features from corpus. corpus is the variable that contains our clean dataset with all the stop words removed.
tfidf.fit_transform is used to extract the words from the texts (features) and transform them into numeric values, which our model can understand.
We finally convert our feature into an array for it to become machine-readable. Arrays can be easily be loaded into our model.
To see our array of features, use this command:
Xfeatures
The output is as shown:
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],])
Getting labels
Labels are the outputs we are trying to predict. Our labels are: mysql, python and php.
y = df[['mysql', 'python', 'php']]
Dataset split
We split the dataset into train set and test set.
We will use the train set to build our model while the test set gauges the model performance. We use the train_test_split to split our dataset into two. 70% of the dataset is used as the train set, and 30% as the test set.
X_train,X_test,y_train,y_test = train_test_split(Xfeatures,y,test_size=0.3,random_state=42)
Building the model
We will build our model using problem transformation techniques.
Let's start with the first technique.
Binary relevance technique
This is used to convert our multi-label problem to a multi-class problem. Let's initialize this technique.
binary_rel_clf = BinaryRelevance(MultinomialNB())
We also add the MultinomialNB() method. MultinomialNB() is the Naive Bayes algorithm method used for classification.
This is important because by converting our multi-label problem to a multi-class problem, we need an algorithm to handle this multi-class problem.
Model fitting
We fit the model into the dataset to recognize patterns from the dataset and learn on its own.
binary_rel_clf.fit(X_train,y_train)
After training, this is the output.
BinaryRelevance(classifier=MultinomialNB(alpha=1.0, class_prior=None,
fit_prior=True),
require_dense=[True, True])
As shown, it uses the MultinomialNB() to handle the converted multi-class problem.
Testing our model
We test our model using the test data. We see if the model can make a prediction using the test data.
br_prediction = binary_rel_clf.predict(X_test)
The get the prediction output in the form of an array, use this command.
br_prediction.toarray()
The output is shown:
array([[1., 0., 1.],
[1., 0., 1.],
[1., 1., 0.],
[1., 0., 1.],
[1., 0., 1.],
[1., 0., 1.],
[1., 0., 1.],
[1., 1., 0.],
[1., 1., 0.],
[1., 0., 1.],
[1., 0., 1.],
[1., 0., 1.],
[1., 0., 1.],])
The above output shows how our model has classified our different text into three categories. If a text belongs to that particular category it's assigned 1, otherwise, it's assigned 0.
Let's calculate the accuracy score.
Accuracy score
accuracy_score(y_test,br_prediction)
The output:
0.9090909090909091
This shows that our model has an accuracy score of 90.91. This is a good accuracy for our model, and our model has a higher chance of making accurate predictions.
Getting hamming loss
Hamming loss is used to determine the fraction of incorrect predictions of a given model. The lower the hamming loss, the better our model is at making predictions.
hamming_loss(y_test,br_prediction)
The output is as shown.
0.06060606060606061
Hamming loss is the fraction of labels that are incorrectly predicted. We have a hamming loss of 6.06% expressed as a percentage in the output above. This shows that only 6.06% of the predictions were wrong out of all the predictions.
This percentage is low and shows that our model was well trained. Continuous training will reduce this percentage, making the model more accurate.
Let's go to the next technique.
Classifier chains technique
This technique reserves label correlation, where an output of one classifier is used as the input of the next classifier in the chain. This process occurs in sequential order.
Let's create a function to help us with building our first classifier in the chain.
def build_model(model,mlb_estimator,xtrain,ytrain,xtest,ytest):
clf = mlb_estimator(model)
clf.fit(xtrain,ytrain)
clf_predictions = clf.predict(xtest)
acc = accuracy_score(ytest,clf_predictions)
ham = hamming_loss(ytest,clf_predictions)
result = {"accuracy:":acc,"hamming_score":ham}
return result
The above function uses the multi-label estimator algorithm in building our model. We name the multi-label estimator algorithm as mlb_estimator. We also fit our model into the dataset so that it can understand patterns and learn from them.
After building our first classifier instance using mlb_estimator and fitting it into our train set and test set, we calculate the accuracy score using the accuracy_score method and the hamming loss using the hamming_loss method.
Our function then outputs the calculated accuracy and hamming score.
This is the first classifier. We will use the result of this classifier as the input features for the next classifier.
Next classifier
The build_model function created above is the input for this classifier.
clf_chain_model = build_model(MultinomialNB(),ClassifierChain,X_train,y_train,X_test,y_test)
In this instance, we are using MultinomialNB() as the classification algorithm. We also need to initialize our ClassifierChain() method to show we are dealing with the classifier chains technique.
In this situation, we shall use the following command to have two classifiers chained together to get the final accuracy score.
clf_chain_model
The output is as shown.
{'accuracy:': 0.8409090909090909, 'hamming_score': 0.10606060606060606}
The accuracy score for this technique is slightly lower than that of the binary relevance technique. The accuracy expressed as a percentage is about 84.09%. The hamming loss is 10.6%; this percentage is relatively high compared to the previous technique. This shows that the binary relevance technique is better than the classifier chains technique.
Let's go to the last technique to compare the three techniques and see which one is the best.
Labelpowerset technique
This technique ensures that the generated multi-class classifier is trained on all the possible label combinations in our data. Let's see how it works.
clf_labelP_model = build_model(MultinomialNB(),LabelPowerset,X_train,y_train,X_test,y_test)
We use the MultinomialNB() method as the classification algorithm for our transformed multi-class classifier. We also initialize LabelPowerset to show that we are dealing with the labelPowerset technique.
Finally, we pass our train set, and test set data so that our model can use it for predictive analysis.
Let's get the accuracy score and hamming loss for this technique.
clf_labelP_model
The output is shown:
{'accuracy:': 0.9090909090909091, 'hamming_score': 0.06060606060606061}
This gives an accuracy score of 90.9% which is a good accuracy score. When we compare the three techniques in terms of accuracy score, binary relevance and label powerset techniques will be best suited for multi-label classification due to their higher accuracy score.
This tutorial has shown how to use the problem transformation technique to build a multi-label text classification model.
Making a single prediction
Predictions are used to evaluate a model to see how well it learned.
Getting a sample text
ex1 = df['title'].iloc[0]
This will get the first text from the title column in our dataset: Flask-SQLAlchemy - When are the tables/databases created and destroyed?.
Vectorise our sample text
This converts our sample text into numerical representations to be easily readable by our model.
We use the tfidf.transform() method to convert our text.
vec_example = tfidf.transform([ex1])
Make prediction
We use the binary relevance classifier to make a prediction.
binary_rel_clf.predict(vec_example).toarray()
The output is converted into an array using the toarray() method, as shown.
array([[1., 1., 0.]])
This is an accurate prediction since it matches precisely with the labels available in our dataset.
Conclusion
This tutorial is helpful to someone who wants to learn about multi-label text classification. We started with the difference between multi-class classification and multi-label classification. We then learned about the three different methods used for multi-label classification.
Finally, we were able to make predictions using our model. This gauges the model. If a model can accurately make predictions, the better the model. Using these steps, a reader should comfortably build a multi-label text classification model with scikit-multi learn.
References
- Code implementation for this tutorial
- Scikit-Multilearn documentation
- Multi-label classification basics
- Solving multi-label classification problems
- Multi-label classification techniques
Peer Review Contributions by: Willies Ogola


{kind=link}