Clustering in Unsupervised Machine Learning

Unsupervised learning is a machine learning (ML) technique that does not require the supervision of models by users. It is one of the categories of machine learning. The other two categories include reinforcement and supervised learning. <!--more-->
Introduction to unsupervised machine learning
In unsupervised machine learning, we use a learning algorithm to discover unknown patterns in unlabeled datasets.
This is contrary to supervised machine learning that uses human-labeled data. Unsupervised learning algorithms use unstructured data that's grouped based on similarities and patterns.
Why unsupervised learning is important
Unsupervised learning is an important concept in machine learning. It saves data analysts’ time by providing algorithms that enhance the grouping and investigation of data. It's also important in well-defined network models. Many analysts prefer using unsupervised learning in network traffic analysis (NTA) because of frequent data changes and scarcity of labels.
It's needed when creating better forecasting, especially in the area of threat detection. This can be achieved by developing network logs that enhance threat visibility.
This category of machine learning is also resourceful in the reduction of data dimensionality. We need dimensionality reduction in datasets that have many features. Unsupervised learning can analyze complex data to establish less relevant features. The model can then be simplified by dropping these features with insignificant effects on valuable insights.
For example, an e-commerce business may use customers’ data to establish shared habits. Using algorithms that enhance dimensionality reduction, we can drop irrelevant features of the data such as home address to simplify the analysis.
Clustering analysis
Clustering is the process of dividing uncategorized data into similar groups or clusters. This process ensures that similar data points are identified and grouped. Clustering algorithms is key in the processing of data and identification of groups (natural clusters).
The following image shows an example of how clustering works.

The left side of the image shows uncategorized data. On the right side, data has been grouped into clusters that consist of similar attributes.
Why clustering is important
Clustering is important because of the following reasons listed below:
-
Through the use of clusters, attributes of unique entities can be profiled easier. This can subsequently enable users to sort data and analyze specific groups.
-
Clustering enables businesses to approach customer segments differently based on their attributes and similarities. This helps in maximizing profits.
-
It can help in dimensionality reduction if the dataset is comprised of too many variables. Irrelevant clusters can be identified easier and removed from the dataset.
Types of clustering in unsupervised machine learning
The main types of clustering in unsupervised machine learning include K-means, hierarchical clustering, Density-Based Spatial Clustering of Applications with Noise (DBSCAN), and Gaussian Mixtures Model (GMM).
K-Means clustering
In K-means clustering, data is grouped in terms of characteristics and similarities. K is a letter that represents the number of clusters. For example, if K=5, then the number of desired clusters is 5. If K=10, then the number of desired clusters is 10.
Key concepts
Squared Euclidean distance and cluster inertia are the two key concepts in K-means clustering. Learning these concepts will help understand the algorithm steps of K-means clustering.
- Squared Euclidean distance: If we have two points x and y, and the dimensional space given by m, the squared Euclidean distance will be given as:

- Cluster inertia: This refers to the Sum of Squared Errors in the cluster. We give the cluster inertia as:

In the equation above, μ(j) represents cluster j centroid. If x(i) is in this cluster(j), then w(i,j)=1. If it's not, then w(i,j)=0.
Based on this information, we should note that the K-means algorithm aims at keeping the cluster inertia at a minimum level.
Algorithm steps
-
Choose the value of K (the number of desired clusters). We can choose the optimal value of K through three primary methods: field knowledge, business decision, and elbow method. The elbow method is the most commonly used. We can find more information about this method here.
-
Select K number of cluster centroids randomly.
-
Use the Euclidean distance (between centroids and data points) to assign every data point to the closest cluster.
-
Recalculate the centers of all clusters (as an average of the data points have been assigned to each of them).
-
Steps 3-4 should be repeated until there is no further change.

Advantages
- It is very efficient in terms of computation
- K-Means algorithms can be implemented easily
Disadvantages
- K-Means algorithms are not effective in identifying classes in groups that are spherically distributed.
- The random selection of initial centroids may make some outputs (fixed training set) to be different. This may affect the entire algorithm process.
Hierarchical Clustering
In this type of clustering, an algorithm is used when constructing a hierarchy (of clusters). This algorithm will only end if there is only one cluster left.
Unlike K-means clustering, hierarchical clustering doesn't start by identifying the number of clusters. Instead, it starts by allocating each point of data to its cluster.
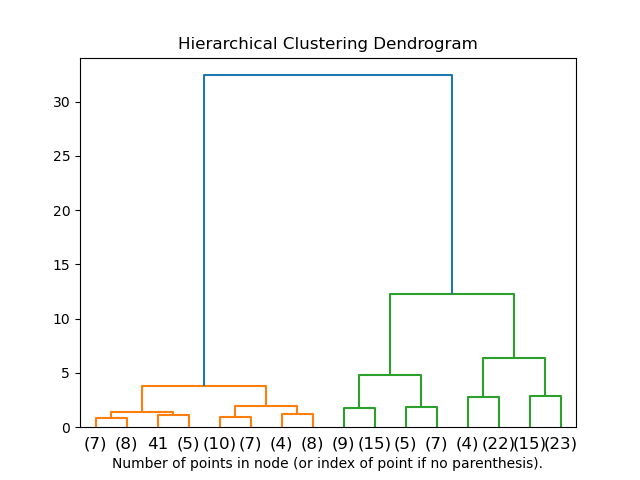
A dendrogram is a simple example of how hierarchical clustering works.

In the diagram above, the bottom observations that have been fused are similar, while the top observations are different.
Algorithm steps
-
Allocate each data point to its cluster.
-
Use Euclidean distance to locate two closest clusters. We should merge these clusters to form one cluster.
-
Determine the distance between clusters that are near each other. We should combine the nearest clusters until we have grouped all the data items to form a single cluster.
Advantages
- The representations in the hierarchy provide meaningful information.
- It doesn't require the number of clusters to be specified.
- It's resourceful for the construction of dendrograms.
Disadvantages
-
Hierarchical models have an acute sensitivity to outliers. In the presence of outliers, the models don't perform well.
-
The computation need for Hierarchical clustering is costly.
Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
This is a density-based clustering that involves the grouping of data points close to each other. We mark data points far from each other as outliers. It then sort data based on commonalities.
Key concepts
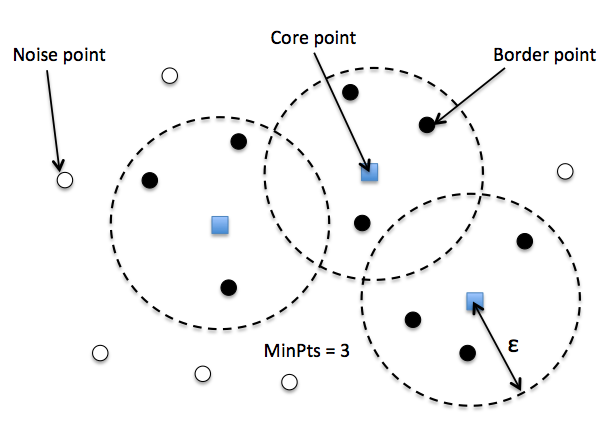
MinPts: This is a certain number of neighbors or neighbor points
Epsilon neighbourhood: This is a set of points that comprise a specific distance from an identified point. The distance between these points should be less than a specific number (epsilon).
Core Point: This is a point in the density-based cluster with at least MinPts within the epsilon neighborhood.
Border point: This is a point in the density-based cluster with fewer than MinPts within the epsilon neighborhood.
Noise point: This is an outlier that doesn't fall in the category of a core point or border point. It's not part of any cluster.
Algorithm steps
- In the first step, a core point should be identified. The core point radius is given as ε. Create a group for each core point.
- Identify border points and assign them to their designated core points.
- Any other point that's not within the group of border points or core points is treated as a noise point.

Advantages
- It doesn't require a specified number of clusters.
- It's very resourceful in the identification of outliers.
- It offers flexibility in terms of the size and shape of clusters.
Disadvantages
-
It's not effective in clustering datasets that comprise varying densities.
-
Failure to understand the data well may lead to difficulties in choosing a threshold core point radius.
-
In some rare cases, we can reach a border point by two clusters, which may create difficulties in determining the exact cluster for the border point.
Gaussian Mixture Models (GMM)
This is an advanced clustering technique in which a mixture of Gaussian distributions is used to model a dataset. These mixture models are probabilistic. GMM clustering models are used to generate data samples.
In these models, each data point is a member of all clusters in the dataset, but with varying degrees of membership. The probability of being a member of a specific cluster is between 0 and 1.
In Gaussian mixture models, the key information includes the latent Gaussian centers and the covariance of data. This makes it similar to K-means clustering.
The following diagram shows a graphical representation of these models.

Algorithm steps
- Initiate K number of Gaussian distributions. This is done using the values of standard deviation and mean.
- Expectation Phase-Assign data points to all clusters with specific membership levels.
- Maximization Phase-The Gaussian parameters (mean and standard deviation) should be re-calculated using the ‘expectations’.
- Evaluate whether there is convergence by examining the log-likelihood of existing data.
- Repeat steps 2-4 until there is convergence.
Advantages
- It offers flexibility in terms of size and shape of clusters.
- Membership can be assigned to multiple clusters, which makes it a fast algorithm for mixture models.
Disadvantages
- If a mixture consists of insufficient points, the algorithm may diverge and establish solutions that contain infinite likelihood. This may require rectifying the covariance between the points (artificially).
- A sub-optimal solution can be achieved if there is a convergence of GMM to a local minimum.
Conclusion
We need unsupervised machine learning for better forecasting, network traffic analysis, and dimensionality reduction. Clustering algorithms in unsupervised machine learning are resourceful in grouping uncategorized data into segments that comprise similar characteristics.
We can use various types of clustering, including K-means, hierarchical clustering, DBSCAN, and GMM. We can choose an ideal clustering method based on outcomes, nature of data, and computational efficiency.
Resources
Peer Review Contributions by: Lalithnarayan C


{kind=link}
{kind=link}